Generating tokens with transformer-based autoregressive language models (LMs) is costly due to the self-attention mechanism that attends to all previous tokens. To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference.
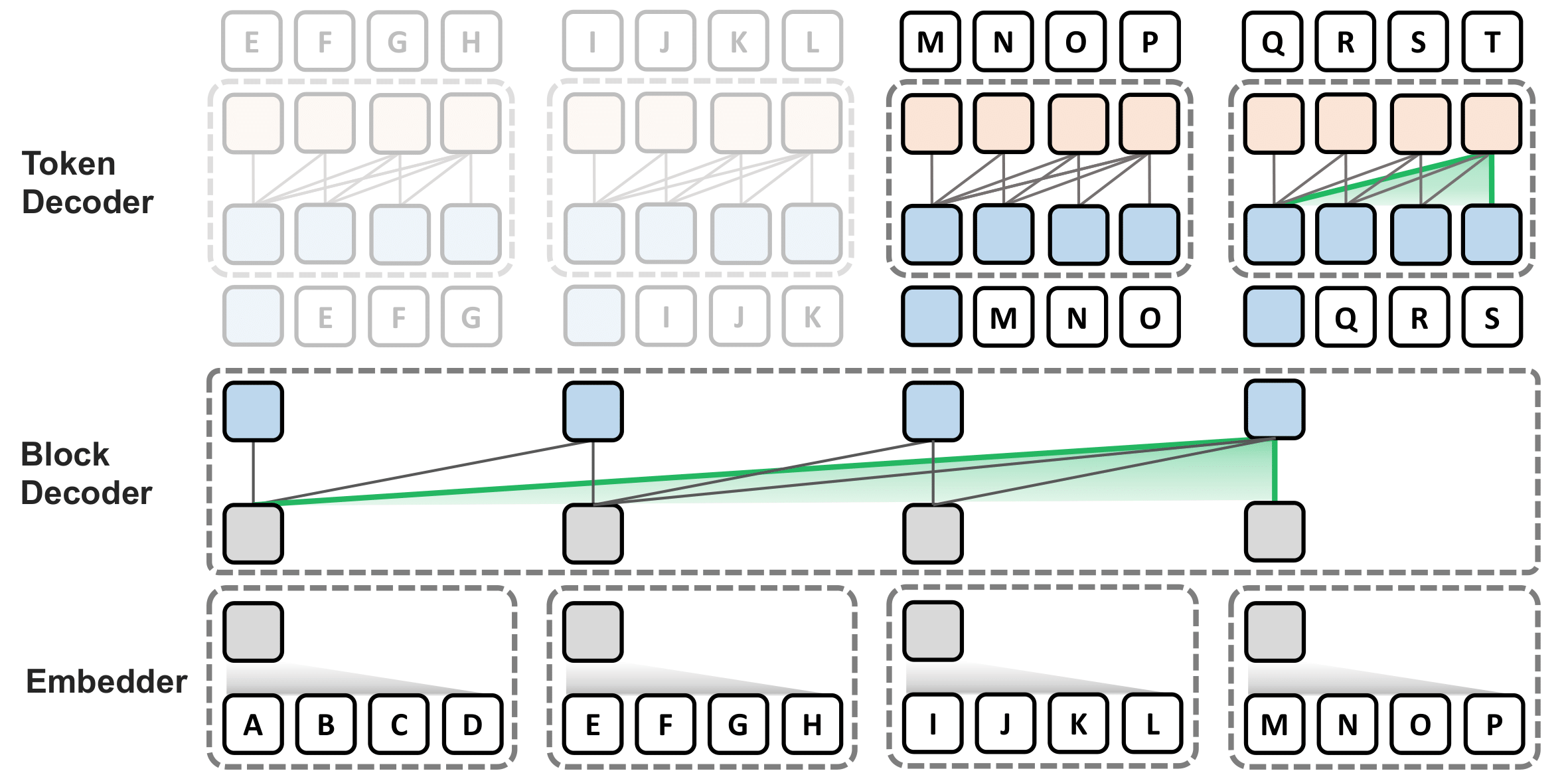
To address this issue researchers have introduced Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention. The Block Transformer architecture introduces a novel approach to modeling global dependencies by using self-attention between coarse blocks at lower layers and decoding fine-grained tokens within local blocks at upper layers. Here’s how it works:
Embedding Blocks: The architecture first embeds each block of input tokens into an input block embedding using a module called the embedder.
Block Decoder: This is an autoregressive transformer that operates on the block embeddings. It applies self-attention between blocks to decode a context block embedding, which contains information necessary for predicting the next block.
Token Decoder: This component autoregressively decodes the token contents of the next block, applying local self-attention between only the tokens within the block. It relies solely on the output block embedding for global context information.
This design significantly reduces self-attention costs, making them linear to the total context length, and eliminates the need to prefill prompt tokens during inference.
By leveraging global and local modules, the Block Transformer architecture demonstrates 10–20x gains in inference throughput compared to vanilla transformers with equivalent perplexity. Block Transformer architecture introduces a new approach to optimize language model inference through novel application of global-to-local modeling.
Paper : https://arxiv.org/pdf/2406.02657